




近年、人工知能(AI)の進歩により、様々な領域で驚くべき成果が得られています。その中でも、AIがスポーツ予測やギャンブルのような不確実性の高い領域での活躍が注目されています。ドワンゴがAIで競馬を当てるという挑戦を行っていましたね。この記事では、機械学習の手法の一つであるWebスクレイピングに焦点を当ててみます。以下は、その解説の導入部分です。
こちらの記事の続きとなります。

導入
今回は教師あり学習を選択することにしたので教師データが必要になります。今回の教師データはいアマまでのtotoの過去のデータを取得する必要があります。どうやって取得するかですが本記事ではWebスクレイピングという手法に焦点を当て、その基本的な考え方と実装方法について解説します。
Webスクレイピングとは?
Webスクレイピングは、ウェブサイトから情報を抽出するためのコンピュータープログラム技術です。この技術を使用することで、特定のウェブページから必要なデータを収集し、そのデータを分析や他の用途に活用することができます。Webスクレイピングは、情報収集や競合分析、データマイニングなど、さまざまな目的で使用されます。
Webスクレイピングの手順
- HTTPリクエストの送信: 最初に、目的のウェブサイトにHTTPリクエストを送信します。これにより、ウェブサーバーからウェブページのコンテンツが取得されます。
- HTMLの解析: 取得したウェブページのHTMLコードを解析して、必要な情報を含む要素を特定します。通常、HTML解析のためにはライブラリやツールが使用されます。代表的なツールにはBeautifulSoupやScrapyがあります。
- データの抽出: 特定のHTML要素から情報を抽出します。これには、テキスト、画像、リンクなど、さまざまな種類のデータが含まれます。抽出されたデータは、通常、テキストファイルやデータベースに保存されます。
- データの加工: 抽出されたデータが必要な形式になるように、必要な加工や変換が行われます。これには、データのクリーニング、整形、フィルタリングなどが含まれます。
- データの利用: 加工されたデータは、さまざまな目的に使用されます。例えば、分析や可視化、自動化されたタスクの実行などです。
Webスクレイピングの注意点
- 利用規約の遵守: ウェブサイトの利用規約を遵守することが重要です。一部のウェブサイトはスクレイピングを禁止しており、利用規約に違反する場合があります。
- アクセス頻度の制御: 過度なリクエストを送信することで、ウェブサーバーに負荷をかける可能性があります。適切なアクセス頻度を制御することが重要です。
- データの正確性の確認: 取得したデータの正確性を確認することが重要です。ウェブページの構造が変更された場合やデータの更新がない場合がありますので、定期的にデータの確認を行う必要があります。
実装(totoの過去データの取得)
取得先のサイトを眺める
まずは、totoのサイトを実際に見て必要なデータがどこにあるかを確認します。さらに、「開発者ツール」でこの見た目をコードとして記述しているHTMLのほうを確認します。
今回は、それぞれの日程で、どことどこが対戦して、スコアなどを取得できればと思いましたので、このページの一番下で見切れている試合Noからくじ結果までのテーブルの中身が欲しいです。
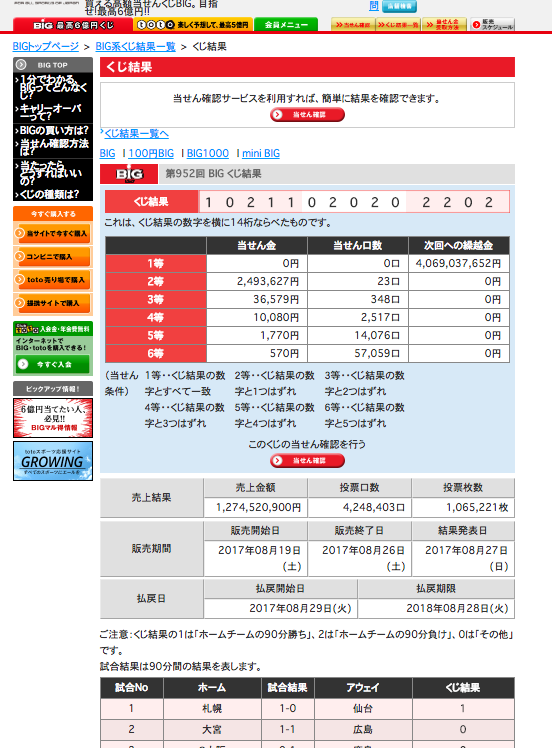

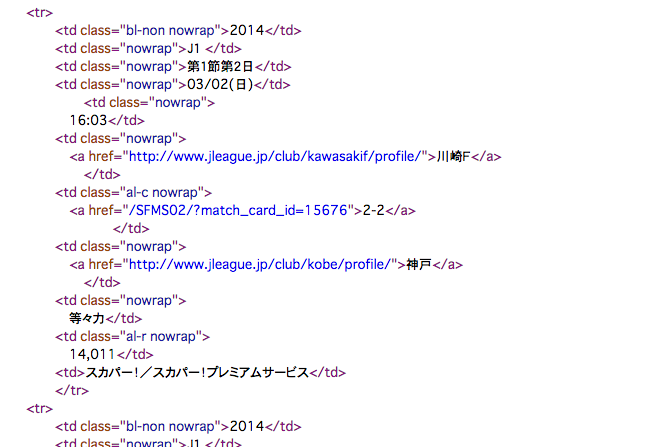
しかし、toto自体の開催回数がそこまで多くないので、別のサイトとしてJリーグのデータサイトからのデータも併用してお借りしたいと思います。そちらのサイトのHTMLはこのようになっています。
プログラム実装
Pythonを用いたWebスクレイピングの実装は比較的簡単です。以下は、requestsとBeautifulSoupを使ってWebページからデータを取得する例です。
# coding=utf-8
import requests
import datetime
from bs4 import BeautifulSoup
import csv
def main():
Year = "2006"
day = datetime.datetime.today()
thisyear = day.year
data = []
while True:
target_url = 'https://(パス省略)'
resp = requests.get(target_url)
soup = BeautifulSoup(resp.text)
tables = soup.find_all("table",class_="table-base00 search-table")
for table in tables:
for tr in table.contents[3].contents:
if tr != "\n":
row = [t.text for t in tr.contents if t != '\n']
data.append(row)
Year += 1
if Year <> thisyear:
break
with open('test.csv', 'w') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerows(data)
if __name__ == '__main__':
main()とりあえずこんな感じで書きました。対象パスの中に年度を入れる箇所があったのでwhileで無限ループを作って年度を加算しながら今年まで繰り返すようにしました。
プログラムの各部の簡単な説明
それでは、プログラムの各部分に簡単な説明を行います。以下の2行でページのHTMLの情報を取得してます。
resp = requests.get(target_url)
soup = BeautifulSoup(resp.text)次に対象のタグ(table)かつクラス(table-base00 search-table)を持つところを抽出しています。
tables = soup.find_all("table",class_="table-base00 search-table")以下の行で情報をリスト化しています。内包表記という書き方で書いています。
row = [t.text for t in tr.contents if t != '\n']上の内包表記は以下のプログラムと同義です。
row = []
for t in tr.contents:
if t != '\n':
row.append(t.text)このようにして、requestsでWebページのHTMLを取得し、BeautifulSoupで解析して必要な情報を抽出します。抽出した情報を適切な形式に加工して、機械学習モデルに入力することで、スポーツの勝敗を予測するためのデータセットを作成することができます。
結果はこんな感じです。8000レコードぐらい取得できました。
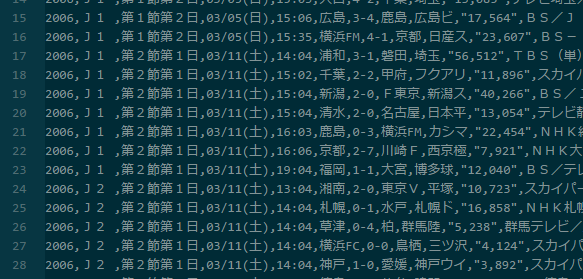
次回の記事では、取得したデータを用いて機械学習モデルを構築し、スポーツの勝敗を予測する手法について詳しく解説します。お楽しみに!

コメント
[…] このサイトが非常に役立ちました。というか、ほぼこのままでいけます。 […]