




はじめに
音声合成技術の進歩は目覚ましく、特に最近では自然な音声を生成できるようになってきました。しかし、実際の音声を編集したり、未知の話者の声で任意のテキストを読み上げさせたりするのは依然として難しい課題です。
本記事では、これらの課題に取り組む最新の研究「VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild」を紹介します。VoiceCraftは、音声編集とゼロショットTTS(Text-to-Speech)の両方で最先端の性能を達成した画期的なモデルです。
VoiceCraftの概要
VoiceCraftは、トークン埋め込み型のニューラルコーデック言語モデル(NCLM)です。主な特徴は以下の通りです:
- Transformer decoderアーキテクチャを採用
- 既存の音声シーケンス内での生成を可能にする独自のトークン並べ替え手法を導入
- 音声編集タスクにおいて、編集された音声が元の録音とほぼ区別がつかないほど自然
- ゼロショットTTSにおいて、VALL-EやXTTS v2などの既存モデルを上回る性能
特筆すべきは、VoiceCraftが多様なアクセント、話し方、録音環境、背景ノイズや音楽を含む現実的で難しいデータセットで一貫して良好なパフォーマンスを示したことです。
技術的詳細
トークン並べ替え手法
VoiceCraftの核となる技術は、以下の2ステップからなるトークン並べ替え手法です:
- 因果的マスキング:マスクされたスパンをマスクトークンに置き換え、シーケンスの末尾に移動
- 遅延スタッキング:コードブックインデックスに基づいて時間次元でトークンをシフト
この手法により、双方向コンテキストを持つ自己回帰的な継続/埋め込み生成が可能になります。
モデリング
VoiceCraftは、トランスクリプト\(W\)と並べ替えられたコーデックマトリックス\(Z\)を入力として受け取り、自己回帰的に\(Z\)をモデル化します。
数学的には、以下のように定式化されます:
$$\mathbb{P}\theta(Z|W) = \prod_s\prod_t\mathbb{P}\theta(Z_{s,t}|W,H_{s,t})$$
$$= \prod_s\prod_t\prod_{k=1}^K\mathbb{P}\theta(Z{s,t,k}|W,H_{s,t})$$
ここで、\(\theta\)はモデルのパラメータ、\(s\)はスパン、\(t\)は時間ステップ、\(k\)はコードブックインデックスを表します。
訓練とインファレンス
訓練時には、ランダムにマスクされたスパンを予測するタスクを行います。インファレンス時には、音声編集の場合は編集対象のスパンをマスクし、ゼロショットTTSの場合は参照音声の後に生成するテキストを配置します。
実験結果
音声編集
VoiceCraftは、人間による聴取テストにおいて、既存の最先端モデルFluentSpeechを大きく上回りました。特筆すべきは、VoiceCraftによって編集された音声が、自然さの面で元の未編集の録音とほぼ区別がつかないレベルに達したことです。
以下の表は、音声編集タスクにおけるVoiceCraftとFluentSpeechの性能比較を示しています
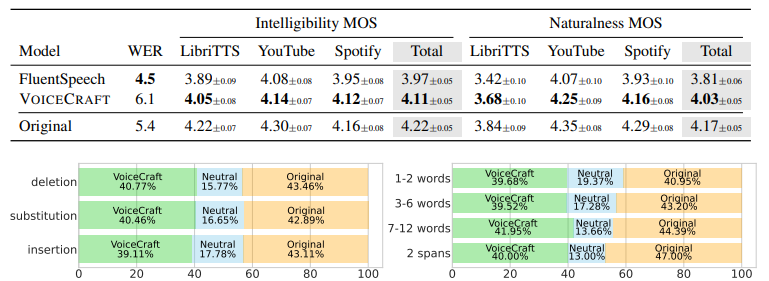
MOSは平均意見スコア(Mean Opinion Score)で、値が高いほど良い性能を示します。
さらに、VoiceCraftとFluentSpeech、およびVoiceCraftとオリジナル音声を直接比較した結果も興味深いものでした:
- VoiceCraftは、FluentSpeechよりも56.1%のケースで好まれ、19.7%のケースで同等と判断されました。
- VoiceCraftによって編集された音声は、オリジナルの未編集音声と比較して、56.4%のケースで同等以上の自然さと判断されました。
ゼロショットTTS
ゼロショットTTSタスクでは、VoiceCraftは客観的指標と主観的指標の両方で最高の結果を達成しました。以下の表は、各モデルの性能比較を示しています:
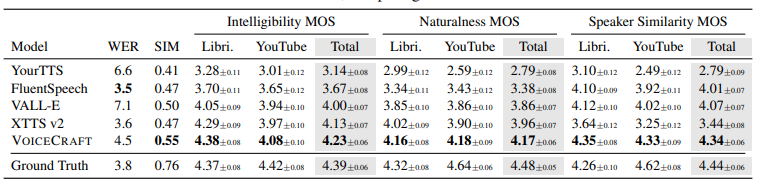
VoiceCraftは、特に話者類似度において優れた性能を示しており、グラウンドトゥルース(実際の人間の音声)に非常に近い評価を得ています。
実装例
VoiceCraftの核となる部分の簡略化したPython実装例を以下に示します:
import torch
import torch.nn as nn
class VoiceCraft(nn.Module):
def __init__(self, vocab_size, d_model, nhead, num_layers):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.transformer = nn.TransformerDecoder(
nn.TransformerDecoderLayer(d_model, nhead),
num_layers
)
self.fc = nn.Linear(d_model, vocab_size)
def forward(self, src, tgt):
src_emb = self.embedding(src)
tgt_emb = self.embedding(tgt)
output = self.transformer(tgt_emb, src_emb)
return self.fc(output)
def generate(self, src, max_len):
device = src.device
batch_size = src.size(0)
src_emb = self.embedding(src)
output = torch.zeros(batch_size, 1, dtype=torch.long, device=device)
for _ in range(max_len):
tgt_emb = self.embedding(output)
dec_output = self.transformer(tgt_emb, src_emb)
logits = self.fc(dec_output[:, -1])
next_token = torch.argmax(logits, dim=-1, keepdim=True)
output = torch.cat([output, next_token], dim=1)
return output[:, 1:]
# モデルのインスタンス化
model = VoiceCraft(vocab_size=10000, d_model=512, nhead=8, num_layers=6)
# 入力データの準備 (仮のデータ)
src = torch.randint(0, 10000, (1, 100)) # バッチサイズ1、長さ100の入力シーケンス
tgt = torch.randint(0, 10000, (1, 50)) # バッチサイズ1、長さ50のターゲットシーケンス
# 順伝播
output = model(src, tgt)
# 生成
generated = model.generate(src, max_len=100)
print(f"Output shape: {output.shape}")
print(f"Generated shape: {generated.shape}")この実装例では、VoiceCraftの基本的な構造を示しています。実際のモデルはより複雑で、トークン並べ替えやマスキングなどの追加機能を含みます。
考察と今後の展望
VoiceCraftは音声編集とゼロショットTTSの両方で優れた性能を示しましたが、いくつかの課題も残されています:
- 生成時に時々発生する長い沈黙や雑音
- AI安全性の問題(音声の透かし入れや検出など)
これらの課題に取り組むことで、VoiceCraftはさらに実用的で安全なツールになる可能性があります。
また、VoiceCraftの登場により、以下のような応用が期待されます:
- 音声障害を持つ人々のためのコミュニケーション支援
- コンテンツクリエイターの編集作業効率化
- 多様なアクセントを含む合成データの生成による音声認識システムの改善
一方で、音声のクローニングが容易になることによる悪用の可能性も懸念されます。これらの倫理的な問題に対処しつつ、技術の恩恵を最大限に活かすバランスが求められます。
まとめ
VoiceCraftは、音声編集とゼロショットTTSの分野に革新をもたらす画期的なモデルです。その高い性能と柔軟性は、音声技術の応用範囲を大きく広げる可能性を秘めています。同時に、この技術の発展に伴う倫理的な課題にも目を向け、責任ある開発と利用を進めていくことが重要です。
今後、VoiceCraftがさらに進化し、より自然で多様な音声生成・編集が可能になることで、コミュニケーションや創造的表現の新たな地平が開かれることが期待されます。


コメント