




近年、自然言語処理の分野で大きな注目を集めているのが、Seq2Seq(Sequence-to-Sequence)モデルです。Seq2Seqは、入力されたテキストデータから、別の形式のテキストデータを生成する手法で、機械翻訳や文章要約、質問応答システムなど、幅広い応用が可能です。本記事では、Seq2Seqの基本概念から数式、Pythonでの実装例まで、詳しく解説していきます。
Seq2Seqとは
Seq2Seqは、入力シーケンスから出力シーケンスを生成するニューラルネットワークモデルです。入力と出力のシーケンス長が異なる場合でも対応できるため、機械翻訳や文章要約など、様々なタスクに適用できます。Seq2Seqは、Encoder-Decoderアーキテクチャを採用し、Attention Mechanismを組み込むことで、より高精度な結果を得ることができます。
Seq2Seqの基本構造
Seq2Seqモデルは、主に2つの部分で構成されています。
- Encoder: 入力シーケンスを固定長のベクトル表現(コンテキストベクトル)にエンコードします。
- Decoder: コンテキストベクトルを元に、出力シーケンスを生成します。
Encoderは、入力シーケンスの各単語を順番に処理し、最終的に入力全体を表現するコンテキストベクトルを生成します。Decoderは、このコンテキストベクトルを初期状態として、出力シーケンスを1単語ずつ生成していきます。
Encoder-Decoderアーキテクチャ
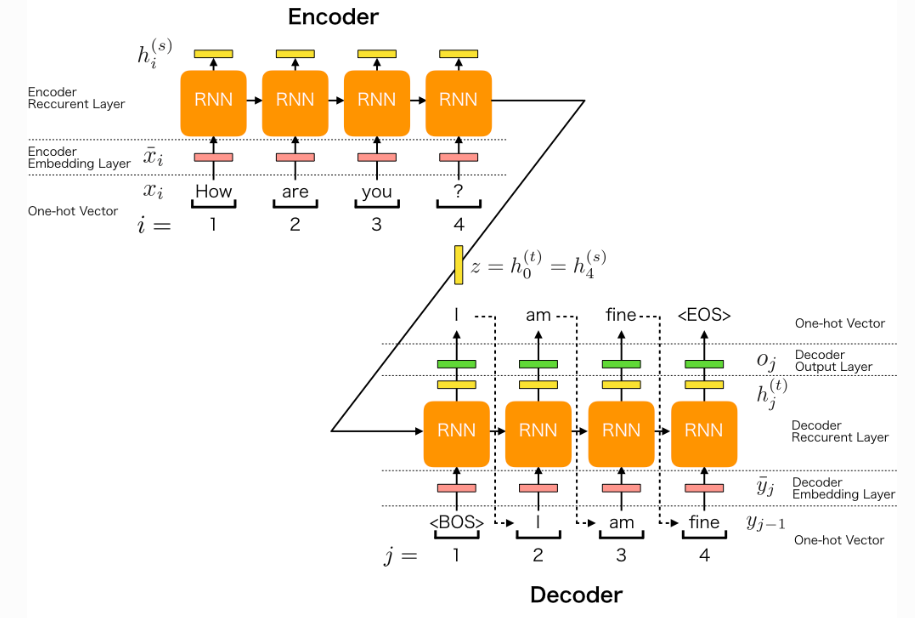

Encoder-Decoderアーキテクチャは、Seq2Seqモデルの中核をなす構造です。EncoderとDecoderは、それぞれRecurrent Neural Network(RNN)やLong Short-Term Memory(LSTM)、Gated Recurrent Unit(GRU)などの再帰型ニューラルネットワークを使用します。
Encoderは、入力シーケンス \(x_1, x_2, \ldots, x_T\) を順番に処理し、各時刻 \(t\) におけるEncoderの隠れ状態 \(h_t\) を計算します。最終的に、Encoderは入力シーケンス全体を表現するコンテキストベクトル \(c\) を出力します。
Decoderは、コンテキストベクトル \(c\) を初期状態として、出力シーケンス \(y_1, y_2, \ldots, y_{T’}\) を生成します。各時刻 \(t\) において、Decoderは前の時刻の出力 \(y_{t-1}\) とコンテキストベクトル \(c\) を入力とし、現在の隠れ状態 \(s_t\) を計算します。そして、この隠れ状態 \(s_t\) から、次の単語 \(y_t\) を予測します。
Attention Mechanism
Attention Mechanismは、Seq2Seqモデルの性能を大幅に向上させる手法です。Attention Mechanismを用いることで、Decoderは入力シーケンスの各単語に対して異なる重みを割り当て、より関連性の高い情報に注目して出力シーケンスを生成できます。
Attention Mechanismでは、各時刻 \(t\) において、Decoderの隠れ状態\(s_t\)とEncoderの各隠れ状態\(h_i\)との間のAttention重み\(\alpha_{ti}\)を計算します。これらのAttention重みを使って、コンテキストベクトル\(c_t\)を計算します。
$$c_t = \sum_{i=1}^{T} \alpha_{ti} h_i$$
このコンテキストベクトル\(c_t\)は、入力シーケンスの関連部分を強調した情報を含んでおり、Decoderはこれを用いて出力シーケンスを生成します。
Seq2Seqの数式表現
Seq2Seqモデルの動作を数式で表現すると、以下のようになります。
Encoderの隠れ状態\(h_t\)は、次の式で計算されます。
$$h_t = f(W_{xh} x_t + W_{hh} h_{t-1} + b_h)$$
ここで、\(f\)は活性化関数(通常はtanhやReLU)\(W_{xh}\) と \(W_{hh}\)は重み行列\(b_h$$はバイアスベクトルです。
Decoderの隠れ状態\(s_t\)は、次の式で計算されます。
$$s_t = f(W_{ys} y_{t-1} + W_{ss} s_{t-1} + W_{cs} c_t + b_s)$$
ここで\(W_{ys}、W_{ss}、W_{cs}\)は重み行列、\(b_s\)はバイアスベクトルです。
出力単語\(y_t\)の確率分布は、Decoderの隠れ状態\(s_t\)からソフトマックス関数を用いて計算されます。
$$p(y_t | y_1, \ldots, y_{t-1}, x) = \text{softmax}(W_{sy} s_t + b_y)$$
Seq2Seqの応用例
Seq2Seqモデルは、様々な自然言語処理タスクに応用されています。
- 機械翻訳: 異なる言語間の翻訳を行います。
- 文章要約: 長い文章を短くまとめます。
- 質問応答システム: 質問に対する回答を生成します。
- 画像キャプション生成: 画像を説明する文章を生成します。
- 音声認識: 音声信号から文字起こしを行います。
Pythonでの実装例
以下は、PytorchでSeq2Seqモデルを実装した簡単な例です。
import torch
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output, hidden = self.gru(embedded, hidden)
return output, hidden
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
output = self.embedding(input).view(1, 1, -1)
output = torch.relu(output)
output, hidden = self.gru(output, hidden)
output = self.softmax(self.out(output[0]))
return output, hiddenこのコードでは、EncoderとDecoderを定義しています。Encoderは入力シーケンスを埋め込み、GRUを使ってコンテキストベクトルを生成します。Decoderは、コンテキストベクトルを元に、出力シーケンスを生成します。
まとめ
Seq2Seqモデルは、自然言語処理の分野で大きな注目を集めている手法です。入力シーケンスから出力シーケンスを生成する能力を持ち、機械翻訳や文章要約など、様々なタスクに応用できます。Encoder-Decoderアーキテクチャを採用し、Attention Mechanismを組み込むことで、より高精度な結果を得ることができます。
本記事では、Seq2Seqの基本概念から数式、Pythonでの実装例まで、詳しく解説しました。Seq2Seqモデルを理解し、自然言語処理の様々なタスクに応用していただければ幸いです。


コメント