




自然言語処理(NLP)の分野で大きな注目を集めているのがword2vecです。word2vecは、単語をベクトル化することで、コンピュータが言語を理解し、処理することを可能にします。この記事では、word2vecの概要、仕組み、そしてPythonでの実装例を紹介します。
word2vecとは

word2vecは、Google社のTomas Mikolovらによって2013年に提案された単語のベクトル表現手法です。この手法は、大量のテキストデータから単語の意味を学習し、各単語を高次元のベクトルで表現します。これにより、単語間の意味的な関係性を数値的に捉えることができます。
word2vecの仕組み
word2vecには、主に2つのアーキテクチャがあります:Continuous Bag-of-Words(CBOW)とSkip-gramです。
CBOW
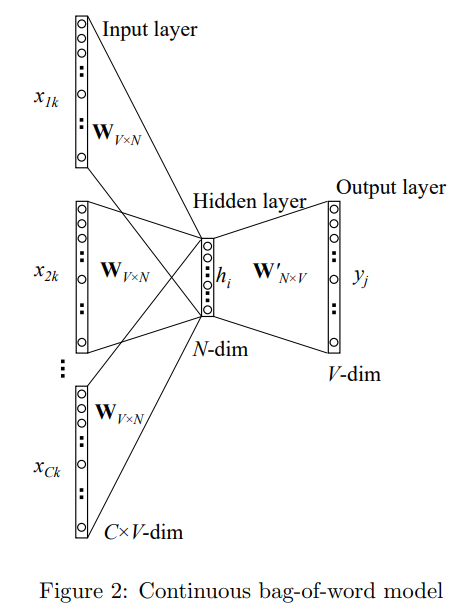
CBOWは、周辺の単語から中心単語を予測するモデルです。例えば、”The cat sits on the mat”という文があった場合、”The”、”sits”、”on”、”the”、”mat”から”cat”を予測します。
Skip-gram
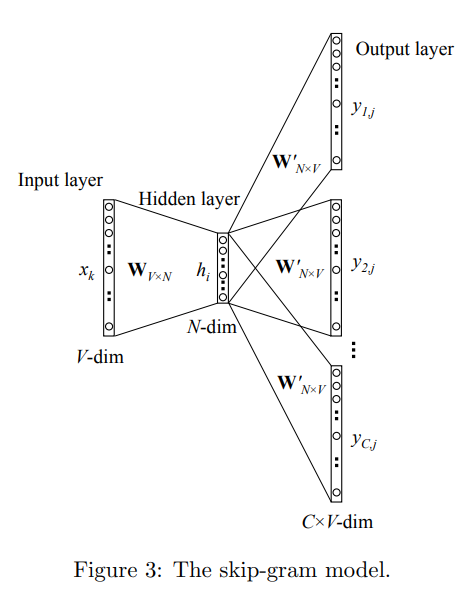
Skip-gramはCBOWの逆で、中心単語から周辺の単語を予測するモデルです。同じ例で言えば、”cat”から”The”、”sits”、”on”、”the”、”mat”を予測します。
これらのモデルを大量のテキストデータで学習させることで、単語のベクトル表現を得ることができます。
数式で表現するword2vec
word2vecは、以下のような目的関数を最適化することで学習されます:
- CBOW: $$J(\theta) = \frac{1}{T} \sum_{t=1}^{T} \log p(w_t | w_{t-k}, …, w_{t-1}, w_{t+1}, …, w_{t+k})$$
- Skip-gram: $$J(\theta) = \frac{1}{T} \sum_{t=1}^{T} \sum_{-k \leq j \leq k, j \neq 0} \log p(w_{t+j} | w_t)$$
ここで、Tはコーパスの単語数、kはウィンドウサイズ、w_tはt番目の単語を表します。
Pythonでのword2vecの実装
Pythonでword2vecを実装するには、genismライブラリを使用するのが一般的です。以下は、簡単な実装例です。
from gensim.models import Word2Vec
sentences = [["cat", "sits", "on", "the", "mat"],
["dog", "runs", "in", "the", "park"]]
model = Word2Vec(sentences, min_count=1)
print(model.wv['cat'])
print(model.wv.most_similar('cat'))上記のコードでは、2つの文からなるリストを用意し、Word2Vecモデルを学習させています。min_countは、出現回数がこの値以下の単語を無視するためのパラメータです。
学習後、model.wv['cat']で”cat”のベクトル表現を取得できます。また、model.wv.most_similar('cat')で、”cat”と意味的に近い単語を見つけることができます。
word2vecの応用例
word2vecは、様々なNLPタスクで活用されています。例えば:
- 文書分類
- 感情分析
- 機械翻訳
- 質問応答システム
- テキスト要約
これらのタスクでは、単語のベクトル表現を入力として使用することで、より高度な言語処理を実現しています。
まとめ
word2vecは、自然言語処理の可能性を大きく広げる技術です。単語をベクトル化することで、コンピュータが言語を理解し、処理することができるようになりました。今回は、word2vecの概要、仕組み、そしてPythonでの実装例を紹介しました。word2vecを活用することで、より高度な自然言語処理システムの構築が可能になるでしょう。


コメント