




Pythonのデータ可視化ライブラリSeabornは、データ分析の効率とわかりやすさを格段に高めてくれます。その中でもdisplotは、分布データの視覚化に特化した非常に便利な機能です。本記事では、displotの基本的な使い方から応用まで、実例を交えながら解説していきます。
カテゴリデータの可視化についてはこちら

displotとは?
displotはSeabornライブラリの中で、1次元の分布を可視化するための便利な関数です。この関数は、ヒストグラムや密度曲線を描画することができ、それらを美しく見栄えの良いグラフにするためのオプションが多数用意されています。以下にdisplotの基本的な使い方と主要なパラメータについて説明します。
displotの種類
分布プロットには、主に3つの種類があります。これに一つのオプションが追加できます。
- histplot() (with kind=”hist”; the default)
- kdeplot() (with kind=”kde”)
- ecdfplot() (with kind=”ecdf”)
- rugplot() (with rug=True)
データの準備
今回は、seabornでサンプルとして準備されているデータを呼び出して使用します。
import seaborn as sns
import matplotlib.pyplot as plt
data = sns.load_dataset("penguins")すべてに共通の引数
- data: プロットするデータのデータフレーム
- x: x軸のカテゴリデータの列名
- rug: Trueを指定すると、x軸上にデータ点を小さな垂線で示します。
histplot:ヒストグラム
histplot()の実装
ヒストグラムは、データの値の出現頻度を高さで表すグラフです。横軸はデータの値を表し、縦軸は各区間の値の出現回数(密度や確率に変換することも可能)を表します。
- データを区間(ビン)に分割し、各ビンの値の出現回数をカウントします。
- ビンの幅が狭いほど詳細な分布を捉えられますが、過度に狭いと雑音が目立ちます。
- ビン数が多すぎると分布の大まかな形を捉えにくくなります。
ヒストグラムは分布の概形をパッと見て把握できる直感的なグラフです。
最小コード
sns.displot(data, x="flipper_length_mm")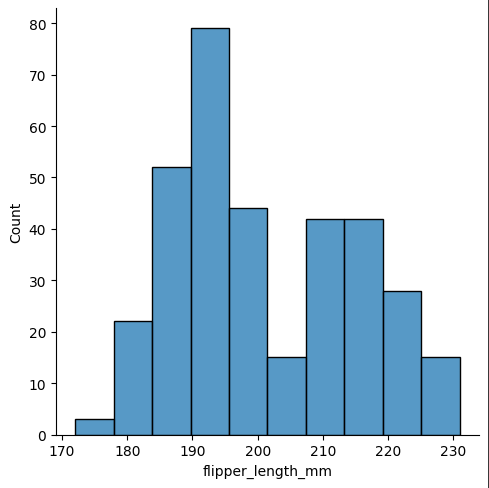
様々なオプション
binwidth
データを区間(ビン)に分割するサイズを変更できる、ただしあまり幅を大きくとりすぎると特徴をうまく捉えられないので注意すること。
sns.displot(data, x="flipper_length_mm", binwidth=20)
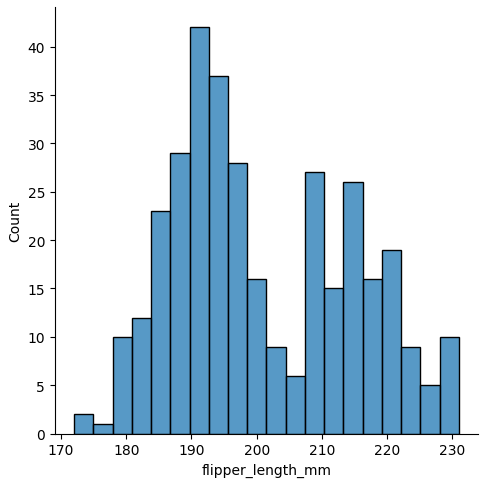
sns.displot(data, x="flipper_length_mm", binwidth=3)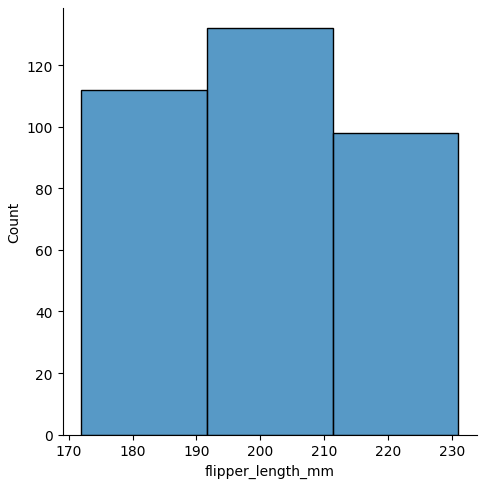
bins
データを区間(ビン)に分割する個数を変更できる、個数から幅を逆算される
sns.displot(data, x="flipper_length_mm", bins=15)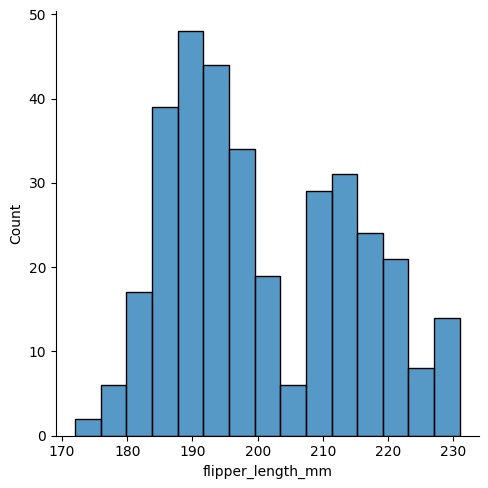
hue
ここに設定した列名のカテゴリに応じて色分けを行うことができる。
sns.displot(data, x="flipper_length_mm", hue="species")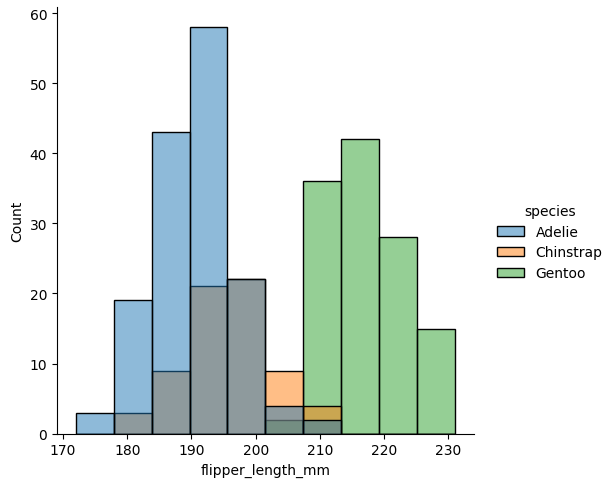
multiple
各バーを重ねる代わりに、バーを「積み重ねる」こともできます。このプロットでは、アウトラインは、変数が1つだけのプロットと一致します。
sns.displot(data, x="flipper_length_mm", hue="species", multiple="stack")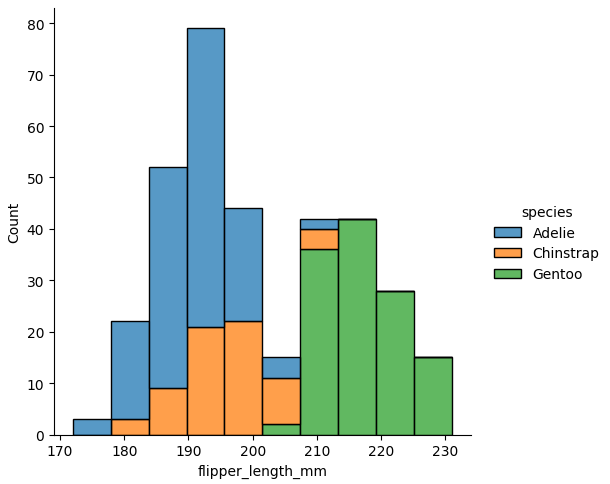
col
各バーを重ねたり、積み重ねたりする代わりに、サブプロットとして別のグラフに分けて表示することも可能です。
sns.displot(data, x="flipper_length_mm", col="species")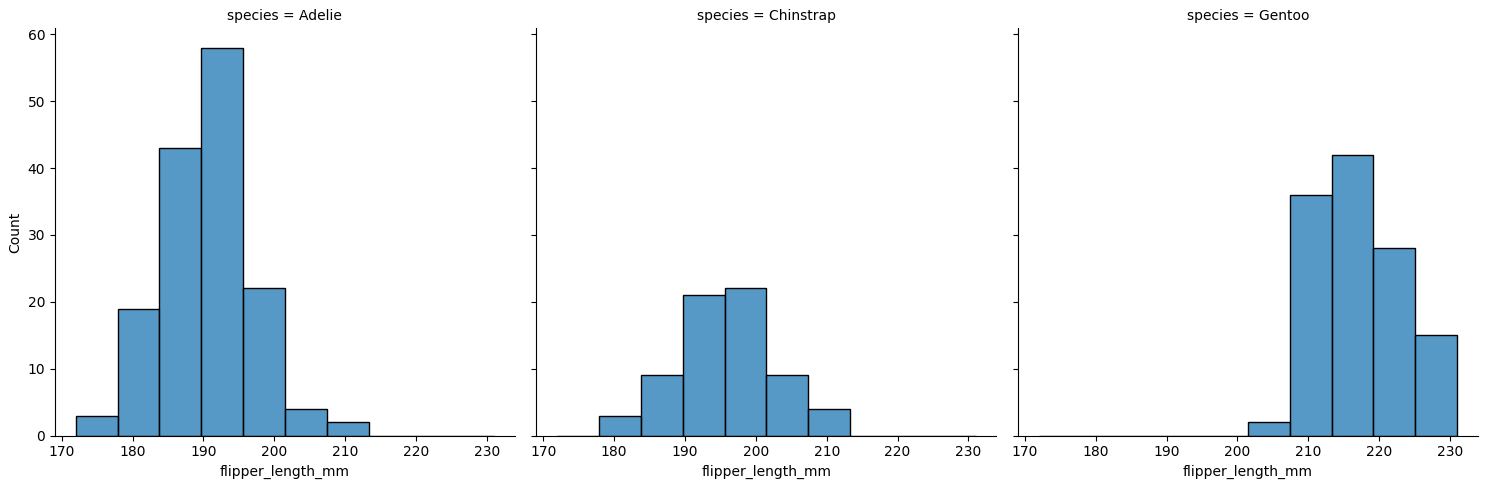
その他オプションによって、正規化することで観測を助ける方法もあります。
kdeplot:カーネル密度推定
kdeplot()の実装
密度曲線は、カーネル密度推定(Kernel Density Estimation: KDE)によってデータの確率密度関数を滑らかな曲線で描画します。
- カーネル関数を使って各データ点の周りに滑らかな曲線を重ね合わせ、密度曲線を推定します。
- ヒストグラムに比べてビン幅の設定に左右されない滑らかな分布を表せます。
- カーネルの種類やカーネル幅のパラメータによって曲線の形状が変わります。
密度曲線は連続的なデータ分布をなめらかに可視化できる利点があります。
最小コード
sns.displot(data, x="flipper_length_mm", kind="kde")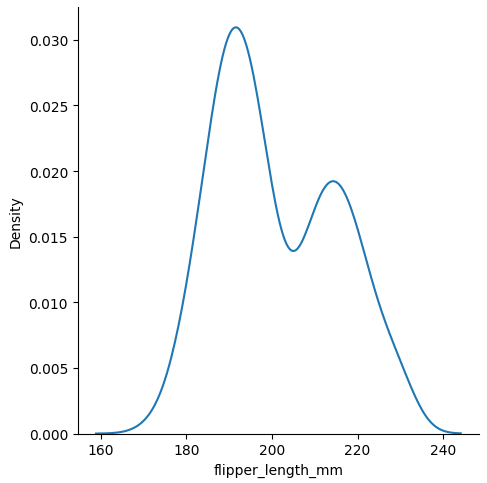
様々なオプション
様々なオプションについては、histplotと同じのものが非常に多いので特に挙動が変わるもの独自のものにのみフォーカスすることにします。
bw_adjust
ヒストグラムのビン幅と同様に、KDEがデータを正確に表現できるかどうかは、平滑化帯域幅の選択に依存します。帯域幅を調整できます。やりすぎには気を付けましょう。
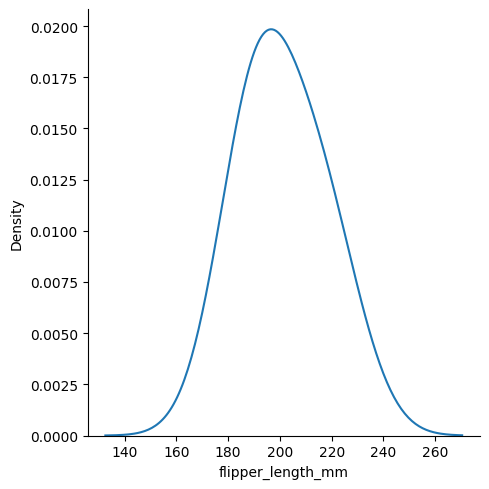
sns.displot(data, x="flipper_length_mm", kind="kde", bw_adjust=.25)
sns.displot(data, x="flipper_length_mm", kind="kde", bw_adjust=3)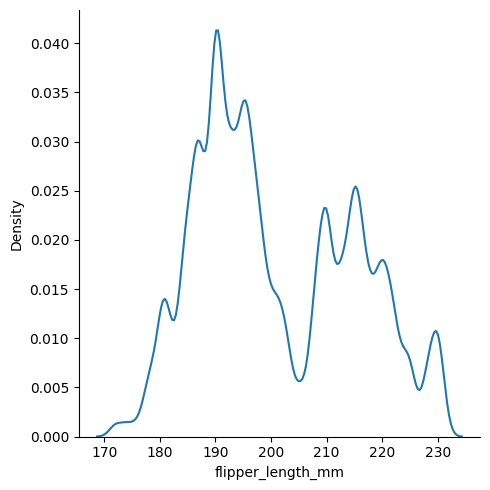
hue
ここに設定した列名のカテゴリに応じて色分けを行うことができる。
sns.displot(data, x="flipper_length_mm", kind="kde", hue="species")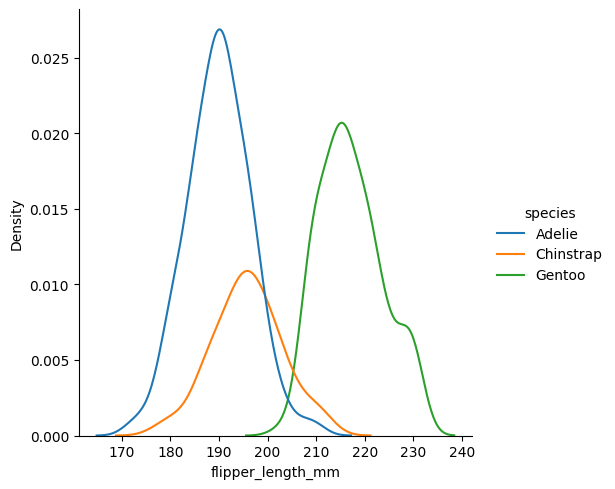
ecdfplot:累積分布関数
ecdfplot() の実装
累積分布関数(ECDF)は、データ点がその値以下になる割合(累積確率)を階段状のグラフで表します。
- データを小さい順に並び替え、各値の累積確率を計算してプロットします。
- 縦軸は累積確率(0から1)を表します。
- データの上側と下側の確率を眺めることができます。
ECDFは、データの全体的な分布や特定の値を下回る確率を視覚的に把握するのに役立ちます。
最小コード
sns.displot(data, x="flipper_length_mm", kind="ecdf")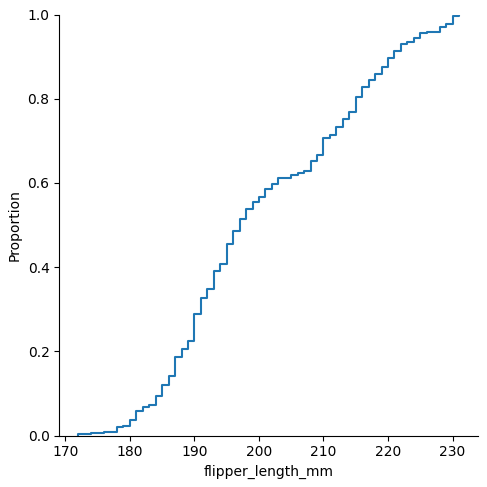
hue
ここに設定した列名のカテゴリに応じて色分けを行うことができる。
sns.displot(data, x="flipper_length_mm", kind="ecdf", hue="species")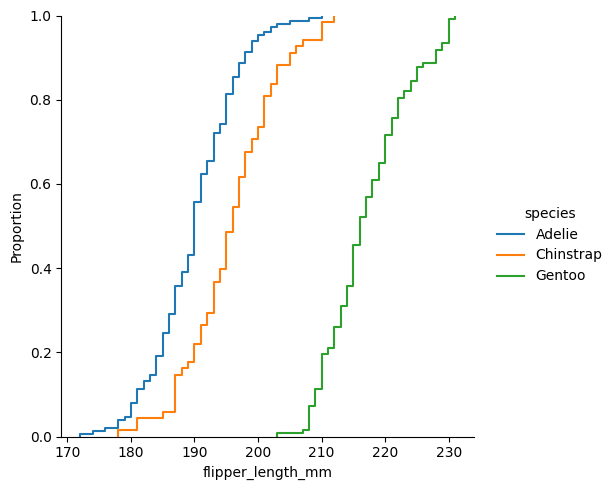
まとめ
displotは、データの分布を可視化するための強力なツールであり、様々な種類のグラフを簡単に作成できることがわかりました。適切に使用することで、データの特徴や傾向を把握し、洞察を得ることができます。

コメント