



様々な生成AIがありますが、その中から今回は絵を生成できる「DCGAN」を実装してピクセルアートを描かせてみたいと思います。
DCGAN (Deep Convolutional GAN)とは
DCGAN(Deep Convolutional GAN)は、『Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks』という論文で提案された、画像生成モデルの一種です。
これは、GAN(Generative Adversarial Network)の改良版であり、基本的なアイデアは同じです。つまり、GeneratorとDiscriminatorを対立させながら、画像の品質を向上させるという手法です。贋作作家が贋作を作り、鑑定士がそれを見抜く、そして贋作作家がさらに巧妙な贋作を作り、鑑定士がそれを見破るといった、いたちごっこを繰り返すことで、より本物に近い贋作が生まれる仕組みです。



全体像
あくまで実装して、実際にどうなったのかについての結果に早めにいきたいのでこの辺りの構造や特徴については詳しく書きません。簡単にどうっていうのだけ書いておきます。DCGANの全体像は、基本的にGANと同じです。唯一の大きな違いは、各ネットワークで全結合層ではなく、畳み込み層や転置畳み込み層が使用されている点です。
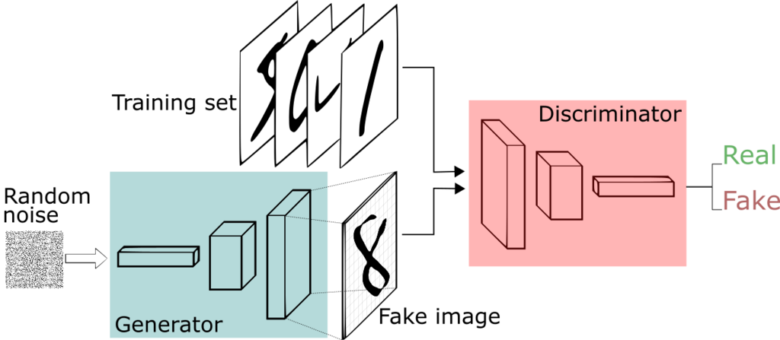
Generator
Generatorのネットワークでは以下の図のように、入力となる100次元のランダムなノイズから64×64サイズの画像を生成します。
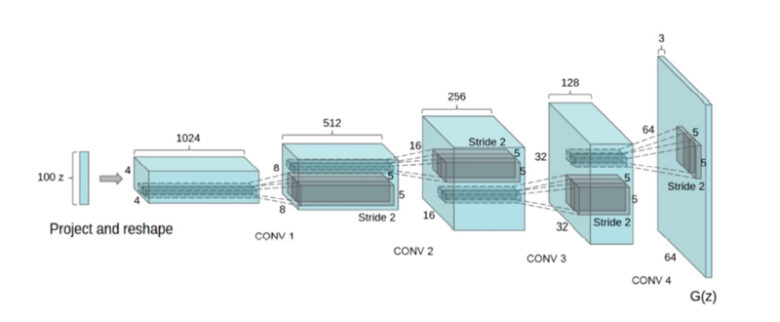
Discriminator
Discriminatorは、画像の識別に畳み込みニューラルネットワークの構造を使用します。これは、Generatorの逆のようなネットワークです。
学習の準備
画像の決定と収集
今回はピクセルアートを作っていきたいと思います。ピクセルアートで再現できたら嬉しいものってなんだろうと考えた結果、個人的に好きなゲームSQUARE ENIXのOCTOPATH TRAVELERのキャラクターを学習データとしてピクセルアートを作ることにします。あ、2も出たよ。
そうと決まったら次はどうやって画像を集めるかだということで、画像を探していたら良さそうなサイトを見つけました。ここからデータをお借りすることにしました。

画像切り抜き
上のような画像を64枚手に入れることができました。ただ、この状態で学習にかけることは難しいので1画像1キャラになるように切り抜いていきたいと思います。もちろん面倒なのでPythonで。
# coding=utf-8
from PIL import Image
import glob
import os
import itertools
def data_create(dir_path):
files = glob.glob(f'{dir_path}/*')
base_pos = [left, upper, right, lower]
span = span
for f in files:
print(f'File "{os.path.basename(f)}" Crop Start!')
im = Image.open(f)
for i, j in list(itertools.product(range(A), range(B))):
print(f'crop number is {i}, {j}')
crop_pos = (base_pos[0] + j * span,
base_pos[1] + i * span,
base_pos[2] + j * span,
base_pos[3] + i * span)
crop = im.crop(crop_pos)
crop = crop.convert("RGB")
crop.save(f'traindata_crop/pixel_art/{os.path.basename(f).replace(".png", "")}-{i}{j}.jpg')
if __name__ == '__main__':
data_create('train_data')このプログラムで、下みたいな画像を切り抜いていくと8000枚ほど集まりました。学習には十分かなということで、学習準備はこれでOKとしましょう。

DCGANの実装
PyTorchの公式の記事にいいものがあるのでそれを利用していこうと思います。正直ほぼほぼコピペで作れたので、実装内容をここに書く必要はないんじゃないかと思うレベルでした。
あと、いつもAIの実装ってプログラム組むこともそうですけど、データの準備をする方が大変だなと思います。
Generatorクラス
# coding=utf-8
import torch.nn as nn
nc = 3
nz = 100
ngf = 64
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, input):
return self.main(input)Discriminatorクラス
# coding=utf-8
import torch.nn as nn
nc = 3
nz = 100
ndf = 64
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)学習
# coding=utf-8
from __future__ import print_function
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
manualSeed = random.randint(1, 10000)
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
dataroot = "/dataset/traindata_crop"
workers = 2
batch_size = 128
image_size = 64
nc = 3
nz = 100
ngf = 64
ndf = 64
num_epochs = 600
lr = 0.0002
beta1 = 0.5
ngpu = 1
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)def train(
netG,
optimizerG,
netD,
optimizerD,
dataloader,
criterion,
fixed_noise,
real_label,
fake_label,
num_epochs
):
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
for epoch in range(num_epochs):
for i, data in enumerate(dataloader, 0):
netD.zero_grad()
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, device=device)
output = netD(real_cpu).view(-1)
errD_real = criterion(output, label)
errD_real.backward()
D_x = output.mean().item()
noise = torch.randn(b_size, nz, 1, 1, device=device)
fake = netG(noise)
label.fill_(fake_label)
output = netD(fake.detach()).view(-1)
errD_fake = criterion(output, label)
errD_fake.backward()
D_G_z1 = output.mean().item()
errD = errD_real + errD_fake
optimizerD.step()
netG.zero_grad()
label.fill_(real_label)
output = netD(fake).view(-1)
errG = criterion(output, label)
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
G_losses.append(errG.item())
D_losses.append(errD.item())
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1
real_batch = next(iter(dataloader))
plt.figure(figsize=(15, 15))
plt.subplot(1, 2, 1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(
np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(), (1, 2, 0)))
plt.subplot(1, 2, 2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1], (1, 2, 0)))
plt.savefig(f"epoch_{epoch}.jpg")
img_list.clear()
torch.save(netG.state_dict(), 'modelG.pth')
torch.save(netD.state_dict(), 'modelD.pth')
return img_list, G_losses, D_lossesdef main():
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
real_batch = next(iter(dataloader))
plt.figure(figsize=(8, 8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(
np.transpose(vutils.make_grid(real_batch[0].to(device)[:64],
padding=2, normalize=True).cpu(), (1, 2, 0)))
plt.show()
netG = Generator(ngpu).to(device)
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
netG.apply(weights_init)
netD = Discriminator(ngpu).to(device)
if (device.type == 'cuda') and (ngpu > 1):
netD = nn.DataParallel(netD, list(range(ngpu)))
netD.apply(weights_init)
criterion = nn.BCELoss()
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
real_label = 1.0
fake_label = 0.0
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
print(netG)
print(netD)
img_list, G_losses, D_losses = train(netG, optimizerG, netD, optimizerD, dataloader,
criterion, fixed_noise, real_label, fake_label, num_epochs)
plt.figure(figsize=(10, 5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses, label="G")
plt.plot(D_losses, label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()if __name__ == '__main__':
main()学習結果
それでは早速学習回数に伴ってどうなってるか見ていこうと思います。64枚1セットの絵を2枚並べてます。左が参考程度に置いている学習元の画像集で右側がAIが作成した画像集です。
Epoch1
やはり最初は、全然ダメですね。

Epoch3
まだまだではありますが、真ん中に何かあればいいんだな?ってことぐらいは学んできましたね。

Epoch16
お?少しキャラらしい何かが見えてきました。

Epoch102
いろんなキャラっぽく見えるようになってきてます。ここまでいけるとは正直思わなかった。写真みたいなものでやったことはありましたが、ピクセルアートできる限り情報を落としたものなので学習ちゃんとできるか不安でしたが安心した。

Epoch139
かなりいい感じにキャラ出来上がってるけど、完璧とは言えない。

一個抜き出して拡大してみてみます。どうでしょう?それなりにいいんじゃないでしょうか?
Epoch158
あれ?なんかノイズ増えてる。

Epoch424
ノイズ増えてきたのでもう過学習になってきてるのか?と思ったので一気に学習回数増やしてどうなるかみてみます。

なぜか全部同じキャラになってしまいました。
まとめ
DCGANを使用してピクセルアートを生成する実験を行いました。初めは乱雑な画像でしたが、学習を重ねるごとにキャラクターらしい特徴が現れてきました。しかし、一定の学習回数を超えると過学習が起こり、予期しない結果が得られることもあります。今後はCycle GANなどの他のアーキテクチャを試して、さらに高度な生成モデルを構築していきたいと考えています。

コメント