




データの可視化は、データ解析の重要なステップです。PythonのSeabornライブラリは、Matplotlibに基づいており、美しいデフォルトスタイルや統計データの視覚化に特化した機能を提供しています。この記事では、Seabornの基本的な使い方を解説し、KaggleのTitanicデータセットを使用して実例を示します。
Seabornとは
Seabornは、Pythonのデータ可視化ライブラリであり、Matplotlibのラッパーライブラリとして機能します。デフォルトで美しいグラフを生成し、統計的なデータを視覚化するための機能を豊富に提供しています。データセットの関係性を調査したり、異なる変数間のパターンを発見したりするのに役立ちます。
インストール
Seabornは、通常、pipコマンドを使用してインストールされます。
pip install seabornデータの概要を確認する
題材はKaggleのTitanicを使うことにします。Titanicってなに?データを読み込むまでの方法は?という方は以前の記事を見てみてください。
まずはじめに、KaggleのTitanicデータセットを使用して、Seabornの機能を実際のデータに適用してみましょう。以下のコードを使用して、データセットを読み込みます。
import seaborn as sns
import pandas as pd
# Reading file
titanic = pd.read_csv("../input/train.csv")データ確認
まずは、どんなデータが入っているのかを確認します。
titanic.head()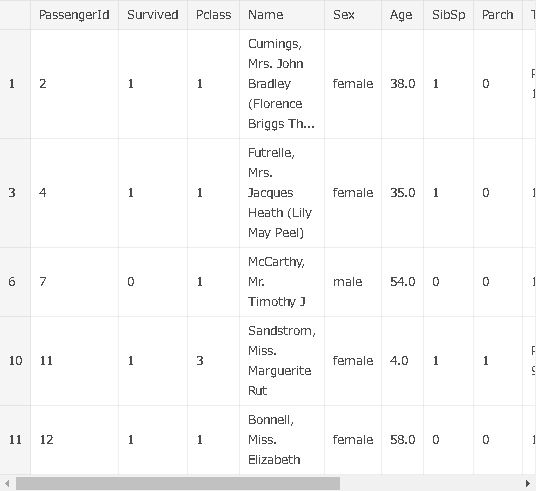
データの可視化
【pairplot】全組み合わせの相関グラフ
データセットの各変数同士の相関分析を簡単に実施できる関数としてpairplotがあります。
sns.pairplot(titanic[["Survived", "Pclass", "SibSp", "Parch", "Age", "Fare"]])
plt.show()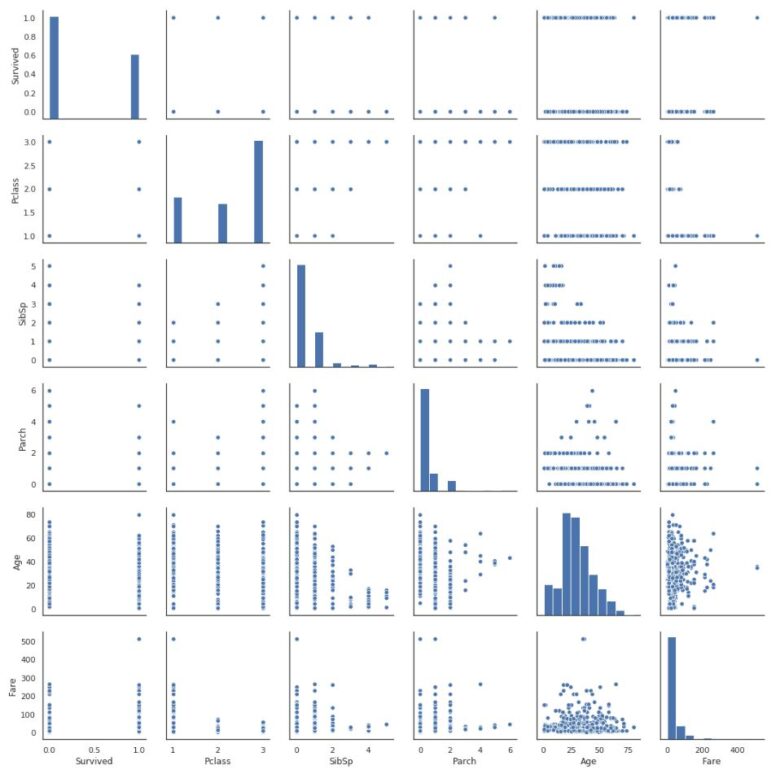
このままだと、分析は不可能なのである項目で色分けします。hue=**というキーワード引数に色分けしたいフィールドを書くとグループごとに色分けされます。
Survivedで色分けしましょう。0が死亡で1が生存なので青が死亡、オレンジが生存となります。
sns.pairplot(titanic[["Survived", "Pclass", "SibSp", "Parch", "Age", "Fare"]],
hue="Survived")
plt.show()
私は統計学のエキスパートではないのでこれを見てもParchのグラフを見るとParchが0の人は生存率が高そう…かな?ぐらいであとはさっぱりです。
この画像を作成するために以前紹介しているmatplotlibを使おうと思うとかなり大変です。subplotでこの数のグラフを準備してそれぞれのデータを入れてフォーマットを整える必要があります。
どうしてもやってみたい方は、こちらの記事を参考にやってみてください。
【catplot】カテゴリーごとの棒グラフ
カテゴリー間の比較や分布を可視化するための有用な手法です。このグラフは、異なるカテゴリーに属するデータポイントの数値的な比較や分布を理解するのに役立ちます。こちらはcatplot関数で対応できます。
1.同乗した兄弟や配偶者の数と生存率
同乗した兄弟や配偶者の数のカテゴリに対して生存したかどうかの推定値(指定しなければ平均値)をプロットするようなコードとその結果です。推定値の周りの信頼区間も計算され、誤差範囲も黒いラインでプロットされます。
sib_s = sns.catplot(x="SibSp",y="Survived", data=titanic, kind="bar", size = 6 )
sib_s = sib_s.set_ylabels("survival prob")
plt.show()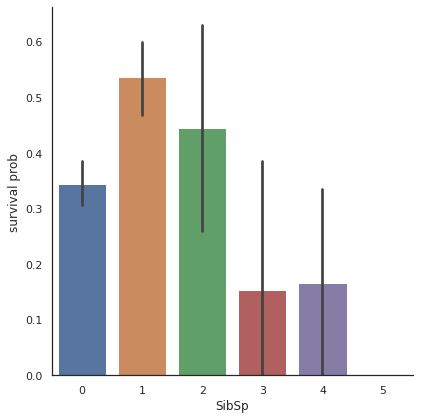
あまり大家族だと生存率は高くないようです。救命ボートに全員で乗りたいが空きがなかったとかが原因なのでしょうか?ただ、そこまで重要なファクターではなさそうです。
2.性別と生存率
では、性別というカテゴリに対して生存したかどうかの推定値をプロットさせます。
s_s = sns.catplot(x="Sex", y="Survived", data=titanic, kind="bar", size=6)
s_s = s_s.set_ylabels("survival prob")
plt.show()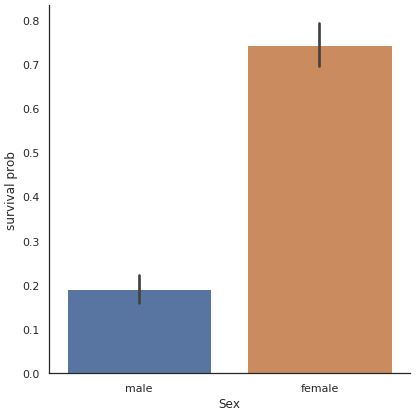
性別で見ると男性の生存率は結構低いことがわかります。
そういえば、ある映画でも描かれてましたが女性と子供を先にボートに乗せてましたね。
とにかく性別はそれなりに重要な特徴変数になりそうです。
3.チケットクラスと生存率
次に、チケットクラス(新幹線でいうと1がグリーン、2が指定席、3が自由席というイメージ)と生存に相関があるかどうかも同様に見ることができます。
c_s = sns.catplot(x="Pclass",y="Survived", data=titanic, kind="bar", size=6)
c_s = c_s.set_ylabels("survival prob")
plt.show()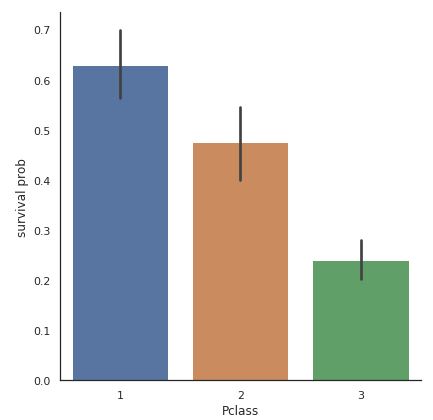
チケットクラスは1等から順に生存率は下がっています。
やはり高いチケットを買った層は優先されているみたいです。
ちなみに、タイタニック号の乗船料金はいくらだったのか?
(※ドル円換算レートは記事作成時のレート[USD/JPY 150.64]を参考にしています。)
- 1等スイート:£870 / $4,350(現在の価値に換算して約750万円)
- 1等:£30 / $150(現在の価値に換算して約26万円)
- 2等:£12 / $60(現在の価値に換算して約10万円)
- 3等:£3 ~ £8 / $15 ~ $40(現在の価値に換算して約3万円~約7万円)
スイートとんでもない値段ですね。
4.性別+チケットクラスと生存率
さらに性別とチケットクラスの組み合わせが生存に相関があるかどうかも同様に見てみましょう。
c_s = sns.catplot(x="Pclass", y="Survived", hue="Sex",
data=titanic, kind="bar", size = 6 )
c_s = c_s.set_ylabels("survival prob")
plt.show()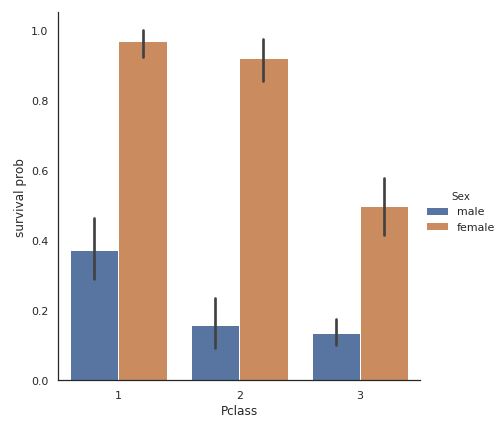
ここで注目するところは、1等チケットを持っている男性よりも3等チケットを持った女性のほうが生存率が高いことです。
このことからチケットの格よりも性別のほうが重要なファクターであることが汲み取れますね。
【countplot】カテゴリごとのカウントグラフ
今度は性別と生死で場合分けを行ってカウントしてくれるcountplotを利用してみます。
前項で男性の生存率は低いことはわかりましたが、男性客が圧倒的に多かったから生存率が低いだけである可能性は捨てきれません。カウントをとってみることで生存数の絶対値が性別による差はなくただ単に男女同じ人数をボートに乗せた結果ではないのか。その場合性別は重要なファクターであるかどうかを再考する必要が出てくるかもしれません。
count_s = sns.countplot(x="Sex", hue="Survived", data=titanic)
plt.show()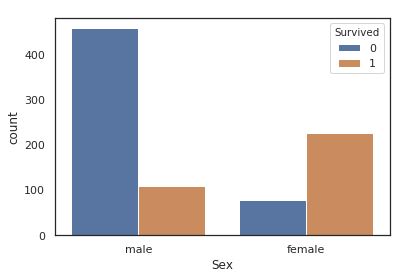
男性が100名程度に対して、女性は200名超の倍以上が助かっています。
この結果からやはり性別は重要なファクターであるといえそうです。
【FacetGrid】属性ごとのグラフ
最後に年齢のように連続値となっているデータにおいて生存率を調べたい場合catplotではうまく可視化できません。そこでFacetGrid関数を用いることで、0-10歳までのグループ、11-20歳までのグループといった属性に分けて、その属性ごとにグラフを描画させます。
無理やりcatplotした結果
Fg = sns.FacetGrid(titanic, col='Survived')
Fg = Fg.map(sns.distplot, "Age")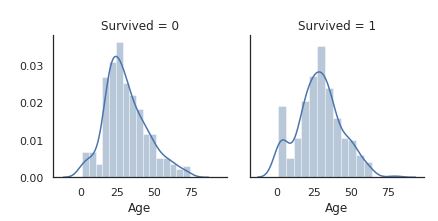
さらに性別で分けて生死で色分けした形で再度描画します。
Fg = sns.FacetGrid(titanic, col='Sex', hue="Survived")
Fg = Fg.map(sns.distplot, "Age").add_legend()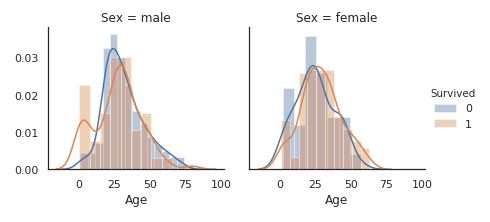
女性だけでなく子供も生存率が高いです。
年齢を10歳刻みで分けてファクターにするのは有効と考えられそうです。
結果
Seabornは、データの可視化を美しくグラフを非常にスマートなコードで実現できることがわかりました。この記事では、Seabornの基本的な使い方として、pairplot、catplot、countplot、FacetGridの4つの例を紹介しました。これらの機能を活用することで、データの傾向や関係性を視覚的に把握できることを実演しました。
Seabornを使ってデータを探索し、パターンを発見し、洞察を得るための幅広い機能が提供されています。データサイエンスや機械学習の分野で作業する際に、Seabornは強力な味方となることでしょう。

コメント