




言語モデル(Language Model, LM)は、近年の人工知能(AI)分野で最も注目を集めている技術の一つです。LMは、大量のテキストデータを学習することで、人間のような自然な言語を生成したり、言語に関する様々なタスクを遂行したりすることができます。この記事では、LMの成り立ちから現状、そしてこの先の展望について大まかに解説していきます。
それぞれのモデルの解説は別の記事を書いていきますので、そちらをご参照ください。
言語モデルとは何か
言語モデルとは、大量のテキストデータから言語の確率分布を学習したモデルのことです。つまり、ある単語や文章が出現する確率を予測することができます。これにより、与えられた文脈に適した自然な言語を生成したり、文章の意味を理解したりすることが可能になります。
LMは、主に2つのタイプに分けられます。統計的言語モデルとニューラル言語モデルです。統計的言語モデルは、単語の出現頻度などの統計情報に基づいて言語を modelingしますが、ニューラル言語モデルは、ディープラーニングを用いて言語の抽象的な特徴を学習します。近年は、ニューラル言語モデルが主流となっています。
言語モデルの歴史と発展
1940年代の統計的手法に始まり、ニューラルネットワークの登場、深層学習の勃興を経て、現在では数百億から数千億のパラメータを持つ大規模言語モデルが開発されるに至りました。
特に2017年のTransformerの登場以降、言語モデルは急速に進化しています。BERTやGPTなどの事前学習済みモデルは、自然言語処理の様々なタスクで従来手法を大幅に上回る性能を達成しました。
ここから各世代での革新的なモデルの出現などを年代ごとにまとめてみました。
統計的言語モデルの時代(1940年代~1980年代)
言語モデルの歴史は、1940年代にさかのぼります。当時は、単語の出現頻度に基づく統計的な手法が用いられていました。その後、1980年代になると、隠れマルコフモデル(HMM)などの確率モデルが導入され、音声認識などの分野で活用されるようになりました。
| 1948年 | クロード・シャノンが情報理論を提唱し、言語をモデル化する基礎を築く。 |
| 1950年代 | マルコフ連鎖に基づく言語モデルが登場。 |
| 1980年代 | N-gramモデルが広く使われるようになる。 |
ニューラルネットワークの登場(1990年代~2000年代)
2000年代に入ると、ディープラーニングの発展に伴い、ニューラルネットワークを用いた言語モデルが登場しました。
| 1990年代 | 統計的機械翻訳システムにN-gramモデルが応用される。 RNNが言語モデルに応用され始める。 |
| 2001年 | Bengioらが初のニューラル言語モデルを提案。 |
| 2003年 | Bengioらが単語の分散表現(word embedding)を提案。 |
深層学習の勃興と言語モデルの進化(2010年代)
2013年にはWord2Vecが発表され、単語の意味を低次元のベクトルで表現することが可能になりました。さらに、2017年にはTransformerアーキテクチャが提案され、RNNを用いた従来のモデルよりも高い性能を達成しました。
この2017年のTransformerのアーキテクチャの提案が言語モデルを一気に実用段階に持ち上げたゲームチェンジャー的なもので論文が出た当初本当に衝撃でした。GPTもこの技術がふんだんにつかわれています。
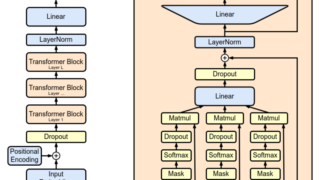
2018年には、BERTと呼ばれる事前学習済みのTransformerベースの言語モデルが発表され、多くのNLP(自然言語処理)タスクで state-of-the-artな結果を達成しました。BERTは、大量のテキストデータを事前学習することで、汎用的な言語表現を獲得し、ファインチューニングによって様々なタスクに適用できるようになりました。
| 2010年 | Mikolovらが再帰型ニューラルネットワーク言語モデル(RNN-LM)を提案。 |
| 2011年 | GoogleがRNN-LMを音声認識に応用。 |
| 2013年 | Mikolovらが Word2Vecを発表し、単語の分散表現が広く利用されるようになる。 |
| 2014年 | ChoらがGRUを、HochreiterらがLSTMを言語モデルに応用。 |
| 2015年 | Vinyalsらが機械翻訳にSeq2Seqモデルを導入。 |
| 2017年 | Vaswaniらが Transformerアーキテクチャを提案。 |
| 2018年 | Devlinらが事前学習済み言語モデルBERTを発表。 |
| 2019年 | Radfordらが GPT-2を発表し、言語生成タスクで人間に近い性能を達成。 |
大規模言語モデルの時代(2020年代~)
2020年代に入り、言語モデルは大規模化の一途をたどっています。GPT-3に代表される数百億から数千億のパラメータを持つモデルが登場し、人間に迫る言語生成能力を示しています。一方で、モデルの大規模化に伴う計算リソースの消費や環境負荷、倫理的な課題なども顕在化しつつあります。今後は、性能追求と並行して、説明可能性や公平性、倫理性といった観点にも注力し、AIと人間の協調を図りながら言語モデルの可能性を追求していくことが期待されています。
| 2020年 | Brownらが GPT-3を発表。1750億のパラメータを持つ大規模モデルが登場。 |
| 2021年 | Fedusらが Switch Transformerを発表。1.6兆のパラメータを持つモデルを学習。 |
| 2022年 | Chowdheryらが PaLM(540B)、Hoffmanらが Chinchilla(700B)を発表。 |
| 2023年 | AnthropicがConstitutional AIの概念を提唱し、倫理的な言語モデルの開発を目指す。 |
現在の言語モデルとその応用
BERTの登場以降、GPT(Generative Pre-trained Transformer)シリーズなど、様々な事前学習済み言語モデルが開発されてきました。これらのモデルは、文章生成、機械翻訳、要約、感情分析、質問応答など、幅広いNLPタスクで活用されています。
特に、最近ではGPT-3やChatGPTのような大規模な言語モデルが注目を集めています。これらのモデルは、数億から数千億のパラメータを持ち、人間に近い自然な言語を生成することができます。また、少量の事例を与えるだけで新しいタスクを学習できる「few-shot learning」の能力を備えています。
言語モデルは、AI分野にとどまらず、ビジネスや社会にも大きな影響を与えつつあります。例えば、カスタマーサポートの自動化、コンテンツ作成の効率化、教育分野での活用など、様々な場面で言語モデルが導入されています。
言語モデルの未来と課題
言語モデルは、今後さらに大規模化・高性能化していくと予想されます。モデルの汎用性が高まることで、より幅広い分野での応用が期待できます。また、few-shot learningやmeta-learningの発展により、少ない学習データでも高い性能を発揮できるようになるでしょう。
一方で、言語モデルには課題も存在します。大規模なモデルの学習には膨大な計算リソースが必要であり、環境負荷やコストの問題があります。また、モデルが学習データに内在するバイアスを引き継ぐことがあり、公平性や倫理的な観点からの配慮が求められます。プライバシーの保護や、モデルの安全性・制御可能性の確保なども重要な課題です。
これらの課題に取り組みながら、言語モデルの研究開発が進められています。AIの説明可能性(Explainable AI)や、人間とAIの協調(Human-AI Collaboration)といった観点も重要視されつつあります。
まとめ
言語モデルは、自然言語処理の分野で大きな躍進を遂げており、様々な応用可能性を秘めています。統計的手法から始まり、ディープラーニングの発展を経て、現在では事前学習済みの大規模モデルが主流となっています。言語モデルは、ビジネスや社会に大きな影響を与えつつあり、今後さらなる発展が期待されます。
一方で、計算リソース、バイアス、プライバシー、安全性などの課題にも直面しています。これらの課題に取り組みながら、言語モデルの可能性を追求していくことが求められています。AIと人間の協調や、説明可能性の向上なども重要なテーマです。
言語モデルの進化は、私たちの生活やコミュニケーションのあり方を大きく変える可能性を秘めています。その発展を見守りながら、AI技術を適切に活用していくことが重要だと言えるでしょう。


コメント