



Stable Diffusionは、テキストからアートを生成するAI技術として大きな注目を集めています。開発元のStability AIが最近、Stable Diffusion 3の研究論文を公開しました。この論文を読み解くことで、次期バージョンでどのような新機能が期待できるのか考察してみます。
パフォーマンスの向上
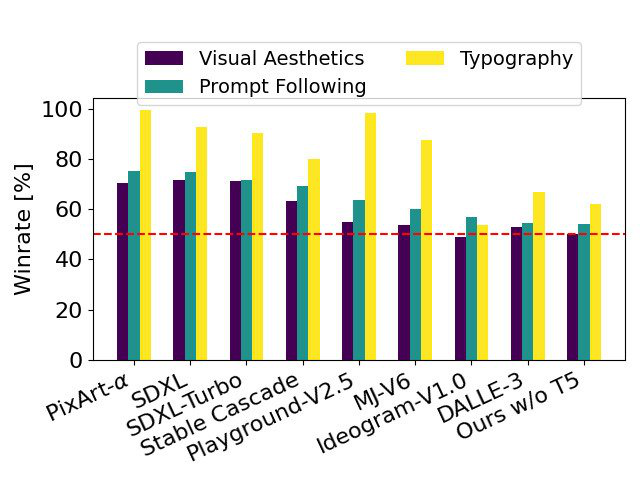
まずは、利用者によるフィードバック(主観)に基づいてパフォーマンスを評価されていました。各モデルからの出力例を見せて、以下の3つのポイントを争点として比較しています。
- prompt following:プロンプトのコンテキストにどれだけ忠実に従っているか
- typography:プロンプトに基づいてテキストがどの程度適切にレンダリングされたか
- visual aesthetics:より美的品質が高いのはどちらか
比較対象は以下の通りです。
- SDXL
- SDXL Turbo
- Stable Cascade
- Playground v2.5
- Pixart-α
- DALL-E 3
- Midjourney v6
- Ideogram v1
Stable Diffusion 3は、現在の最先端のテキストから画像への生成システムと同等またはそれ以上の性能を発揮すると結論付けています。
出力速度の改善
最大のモデルでの出力がRTX 4090の24GB VRAMを使って、50サンプリングステップで解像度1024×1024の条件の画像を生成するのに34秒で完了するようになったそうです。
さらに、Stable Diffusion 3の初期リリース時には、ハードウェアによる制限をなくすため複数のバリエーション(800mから8Bのパラメータモデルまで)が用意される予定とのこと。
GPUは必要でしょうが、それなりのスペックのものでも動くようにしますよっていうアナウンスはとてもうれしいですね。参入障壁が下がります。
階層構造の改善
Multimodal Diffusion Transformer (MMDiT)
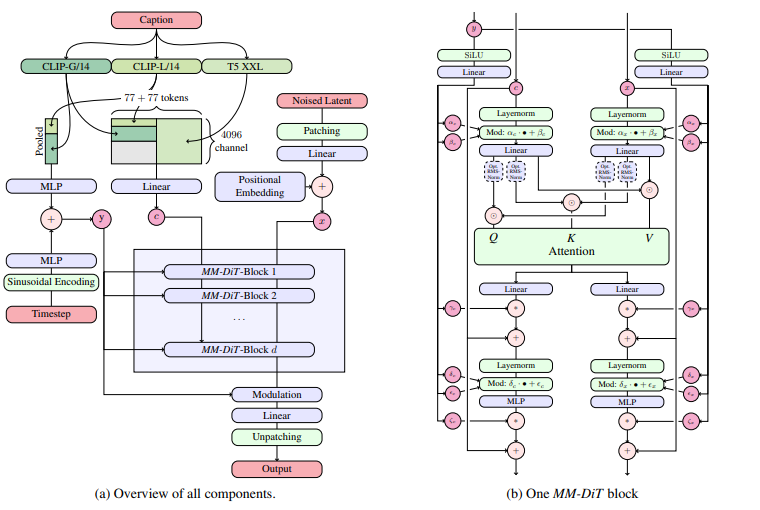
Stable Diffusion 3における大きな改善点の一つとして、より効果的な階層構造の構築が挙げられています。従来のStable Diffusionでは、テキストエンコーダーとイメージディフュージョンモデルが別々に存在していましたが、MMDiTではこれらを1つのマルチモーダルトランスフォーマーに統合しています。
つまり、MMDiTはテキスト・画像の両方の入力を受け取り、それらを単一の潜在空間にマッピングします。そして、この潜在空間内で単一のトランスフォーマーモデルが双方向の注意を行うことで、テキストから画像への条件付けを直接的に行えるようになっています。
この設計により、従来手法に比べて以下のようなメリットが期待できます。
- 複雑な潜在空間構造をシームレスにモデル化できる
- 異なるモダリティ間の相互作用を効果的に捉えられる
- モダリティ固有のモジュールを必要とせず、パラメータを削減できる
結果として、MMDiTは画像生成の表現力やモダリティ間の一貫性を高めながら、同時にモデルの簡素化や効率化も図れる可能性があるアーキテクチャとなる可能性があります。この改善により、構造の複雑なオブジェクトをより高品質に生成できる可能性があります。例えば、人物の顔や手の細かい部分、建物の入り組んだ形状などをよりリアルに表現できるかもしれません。
Rectified Flow Transformer
従来の生成モデルでは、低解像度の潜在空間から徐々に解像度を上げながら画像を生成していました。しかし、このアプローチには解像度が上がるにつれて、情報が失われていく問題がありました。
Rectified Flow Transformerは、この問題を解決するために考案されています。これは以下の2つの主要な技術から成り立っています。
- Rectified Flow
これは画像生成の際の情報損失を最小限に抑えるための手法です。具体的には、ピクセル単位のflow fieldを導入し、各解像度レベルで画像を「整流(rectify)」することで、解像度の上げ下げによる情報損失を防いでいます。 - Conditioning Augmentations
生成される画像の質と多様性を高めるための一連の手法です。学習時に潜在コードにノイズを加えたり、アテンションマスクを適用したりすることで、モデルの表現力と柔軟性を高めています。
このRectified Flow Transformerアーキテクチャを採用することで、従来の手法に比べて高解像度の画像をクリーンに生成できるようになり、かつ表現の多様性も確保できるようになったとされています。
つまり、Stable Diffusionの次期バージョンでこの手法が取り入れられれば、4K超の超高解像度画像生成が実現できる可能性があり、画質と表現力の両面で大きな進化が期待できるというわけです。
Stable Diffusion 3での出力例
アーキテクチャの改良のおかげで、画像自体のスタイルに高い柔軟性を保ちながらさまざまな異なる被写体や品質に焦点を当てた画像を作成できるようになりました。以下が、出力例です。


空間的注意分散の改良
さらに、Stable Diffusion 3では空間的注意分散のメカニズムが改良されています。このメカニズムは、生成画像の各部分に適切な注意を払うことで、矛盾のない完全な画像を出力するのに役立ちます。
論文によると、空間的注意分散のプロセスをさらに洗練させることで、生成物の一貫性と整合性が向上するとされています。つまり、モデルが物体同士の関係性をよりうまく捉えられるようになり、違和感のない自然な画像を生み出せる可能性が高まるということです。
まとめ
Stable Diffusion 3の論文を確認した限り、階層構造の改善、空間的注意の改良、高解像度対応、対象物体への注目機能強化など、さまざまな新機能の搭載が示唆されています。一方で、まだ実験的な段階であり、リリース時期は不透明です。
よりリアルで高品質な画像生成が実現できるであろうStable Diffusion 3の今後の動向に注目したいです。

コメント