



2024年2月、少し話題から遅れましたが、とんでもない論文と大規模言語モデルが公開されました。
このモデルでは、LLMのすべてのパラメータ(または重み)が[-1、0、1]の3値になることで計算速度がかなり向上し、従来のモデルサイズのLLMと同じレベルの精度を持っているとのことです。
個人的には、計算速度が向上するのは確かに想像がつきます。
人で考えても浮動小数点の計算より-1,0,1の計算のほうが早いのは明らかですし。
しかし、精度も同レベルになるのがなぜなんだろうと疑問です。
この疑問を解決するため、公開論文を翻訳して読んでみることで「BitNet b1.58」の概要やどういった技術なのかをまとめます。
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
[2402.17764] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits (arxiv.org)
概要
最近の研究で(例えばBitNetなど)1ビットの大規模言語モデル(LLMs)がLLMの新時代を切り開く手法として注目されています。本研究では、1ビットのLLMの変種であるBitNet b1.58 を紹介します。
このモデルでは、LLMのすべてのパラメータ(または重み)が[-1、0、1]の3つの値になります。モデルサイズとトレーニングトークンが同じである場合、パープレキシティ(テキストをどの程度予測できるかを測る指標)とエンドタスク(未知のタスクを解決する能力)の性能の両方において、従来(16ビット)のLLMと一致します。さらに、遅延、メモリ使用量、処理能力、そしてエネルギー消費の観点から見て、著しくコスト効果が高くなっています。
この技術によりGPUが不要になるかも!と世間で騒がれたのはこの辺を見たからですね。
推論(実際に生成する)の時は確かに不要になる可能性はありそうですが、見たところ依然として学習時などには必要みたいなので、需要がなくなることはないですねきっと。
NVIDIAはまだまだ安泰かも
最近のAI分野では、大規模言語モデル(LLMs)のサイズと能力が急速に拡大しています。これらのモデルは、さまざまな自然言語処理タスクで顕著なパフォーマンスを示していますが、そのサイズの増加により、展開に課題が生じ、高エネルギー消費による環境への影響や経済的影響について懸念が高まっています。
例えば、ChatGPTで有名なモデル、GPT-3.5のパラメータ数は約3550億、GPT-4のパラメータ数は約100兆あるとされていてそれぞれ訓練にかかったコストは非公開だが、その初期版GPT-1はパラメータ1億2000万程度の学習にNVIDIA Quadro P600を8枚30日使用したとのこと
これらの課題に対処するアプローチの1つとして、ポストトレーニング量子化を使用して推論用の低ビットモデルを作成することです。この手法は、重みと活性化の精度を大幅に低下させ、LLMsのメモリと計算要件を大幅に削減できます。BitNetのような1ビットのモデルアーキテクチャに関する最近の研究が、性能を維持しながらLLMsのコストを削減する有望な方向として期待されています。
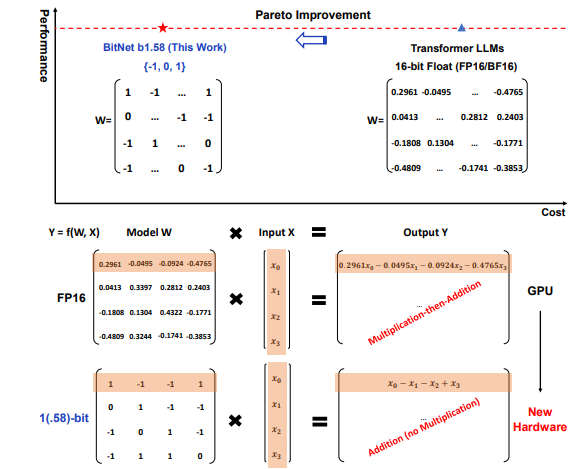
BitNet b1.58の紹介
BitNet b1.58は、nn.LinearをBitLinearに置き換えるTransformerベースのBitNetアーキテクチャに基づいています。このモデルは、1.58ビットの重みと8ビットの活性化関数を持つものとして、ゼロから訓練されました。元のBitNetと比較して、以下の変更が導入されています。
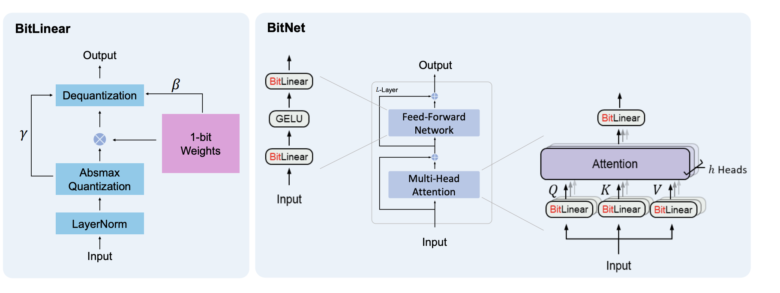
量子化関数
重みが-1、0、または+1のみになるように、absmean量子化関数を採用しています。この関数は、重み行列をその平均絶対値でスケーリングし、それぞれの値を[-1、0、+1]の中で最も近い整数に丸めており、この数式に基づき実装されています。
\(W_f = \text{RoundClip}\left( \frac{W}{\gamma + \epsilon}, -1, 1 \right)\)
\(\text{RoundClip}(x, a, b) = \max(a, \min(b, \text{round}(x)))\)
\(\gamma = \frac{1}{nm} \sum_{ij} |W_{ij}|\)
活性化関数の量子化関数は、BitNetと同じ実装を踏襲していますが、BitNetはnn.Linearの前に活性化を範囲\([0、Qb]\)を行っているのに対して、すべてのトークンごとに範囲\([-Qb、Qb]\)にスケーリングすることで、ゼロポイントの量子化を取り除きました。このアプローチにおいてよりシンプルにすることを可能にしています。
結果
さまざまなサイズの再現されたFP16 LLaMA LLMとBitNet b1.58を以下の条件で比較しました。
- RedPajamaデータセットでモデルを1000億トークンで事前トレーニング
- パープレキシティ検証
- WikiText2
- C4データセット
- 言語タスクのゼロショットパフォーマンス検証
- ARC-Easy
- ARC-Challenge
- Hellaswag
- Winogrande
- PIQA(Physical Interaction Question Answering)
- OpenbookQA
- BoolQ
パープレキシティ検証結果
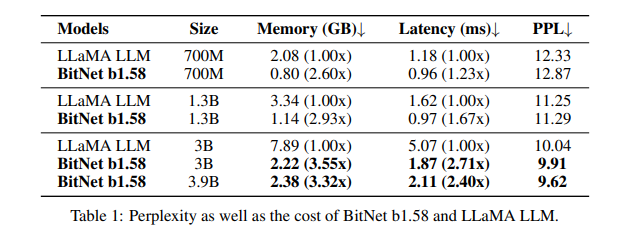
このテーブルの見方ですが、PPLが低いほど良い結果であることを示しています。
BitNet b1.58は、パープレキシティの観点で3BモデルサイズでフルプレシジョンのLLaMA LLMを凌駕し、その上2.71倍高速でGPUメモリの使用量が3.55倍少なくなります。
言語タスクのゼロショットパフォーマンス検証
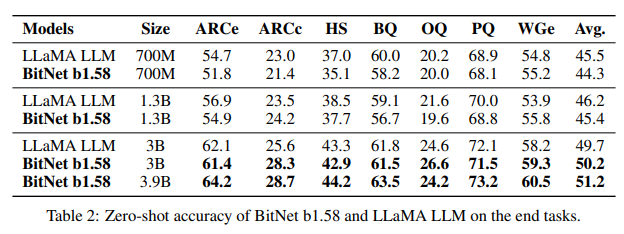
モデルサイズが増加するにつれて、BitNet b1.58とLLaMA LLMのパフォーマンス差が縮まることが見て取れます。
メモリとレイテンシ
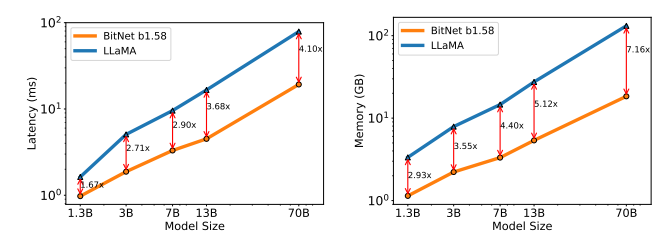
モデルサイズが拡大するにつれて速度が向上することを示しています。特に、BitNet b1.58 70Bは、LLaMA LLMベースラインよりも4.1倍高速です。これは、nn.Linearの時間コストがモデルサイズとともに増加するためです。メモリ消費量も同様の傾向に従います。しかし、コストをさらに削減するための最適化の余地があります。
エネルギー消費
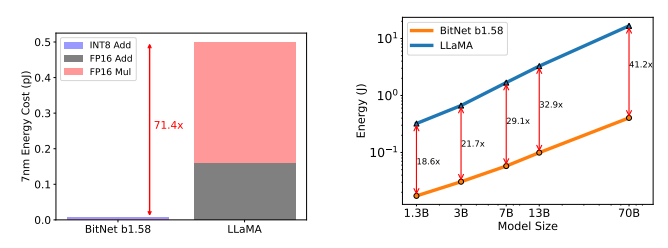
BitNet b1.58の大部分は加算計算であり、LLaMA LLM行列乗算であるため算術演算エネルギー消費量は71.4倍節約できます。モデルサイズが拡大するにつれて、BitNet b1.58がFP16 LLaMA LLMベースラインに比べてエネルギー消費効率が高まることを示しています。
スループット

BitNet b1.58とLLaMA LLMのスループットを、2枚の80GB A100カードで70Bのパラメータを使用して比較すると、BitNet b1.58 70BがLLaMA LLMのバッチサイズの11倍までサポートし、スループットが8.9倍高いことを示しています。
下記は異なるモデルサイズ間の等価性を示しています。
- 13BのBitNet b1.58は、レイテンシ、メモリ使用量、エネルギー消費の点で、3BのFP16 LLMよりも効率的
- 30BのBitNet b1.58は、レイテンシ、メモリ使用量、エネルギー消費の点で、7BのFP16 LLMよりも効率的
- 70BのBitNet b1.58は、レイテンシ、メモリ使用量、エネルギー消費の点で、13BのFP16 LLMよりも効率的
議論と将来の展望
1ビットMixture-of-Experts(MoE)LLMs
Mixture-of-Experts(MoE)は、LLMsにとって費用対効果の高いアプローチであることが証明されています。計算FLOPを大幅に削減しますが、高いメモリ消費量とチップ間通信のオーバーヘッドは、その展開と適用を制限しています。これらの課題は1.58ビットLLMsによって解決できます。まず第一に、メモリのフットプリントを削減することで、MoEモデルを展開するために必要なデバイスの数を減らします。さらに、ネットワーク間でのアクティベーションの転送のオーバーヘッドを大幅に削減します。最終的に、全体のモデルを単一のチップに配置できれば、オーバーヘッドはなくなります。
LLMsにおける長いシーケンスのネイティブサポート
LLMの時代において、長いシーケンスを扱う能力は重要な要求となっています。長いシーケンス推論の主要な課題の1つは、KVキャッシュによって導入されるメモリ消費量です。BitNet b1.58は、16ビットから8ビットへのアクティベーションの削減を通じて、同じリソースを使用してコンテキストの長さを倍増させるという、長いシーケンスのネイティブサポートへの重要な一歩を示しています。これは、1.58ビットLLMsでは、さらに損失なく4ビットまたはそれ以下に圧縮できますが、これは将来の課題として残しています。
エッジとモバイルでのLLMs
1.58ビットLLMsの使用は、エッジおよびモバイルデバイス上の言語モデルの性能を大幅に向上させる可能性があります。これらのデバイスは、しばしばそのメモリと計算能力によって制限され、LLMsの性能とスケールを制限する可能性があります。しかし、1.58ビットLLMsのメモリ消費量とエネルギー消費量の削減により、これらのデバイスに展開できるようになり、これまで不可能だった幅広いアプリケーションを可能にします。これにより、エッジおよびモバイルデバイスの機能が大幅に向上し、LLMsの新しい興奮をもたらす新しいアプリケーションが可能になります。さらに、1.58ビットLLMsは、エッジおよびモバイルデバイスで主に使用されている主要なプロセッサであるCPUデバイスに対してよりフレンドリーです。これは、BitNet b1.58がこれらのデバイスで効率的に実行できることを意味し、それらの性能と機能をさらに向上させます。
1ビットLLMs向けの新しいハードウェア
最近のGroq5などの研究は、LLMs向けの特定のハードウェア(例:LPUs)の構築において有望な結果と大きな潜在能力を示しています。さらに一歩進んで、BitNetで可能になる新しい計算パラダイムを考慮して、1ビットLLMsに特化した新しいハードウェアとシステムを設計するための行動を提唱しています。
まとめ
BitNet b1.58は、低コストで高性能なLLMsを実現するための新しいアプローチを提供しており、将来の言語モデリングの展望に対する新たな見通しを開拓していることが分かりました。
基本フローはLLMの考え方で最後のLinear結合のところをうまく1bitに量子化することでコストを下げているんですね。こういうアイデアが出せるのが本当にすごいです。

コメント